
![]() Everybody updates their code. Some more than others, and many during business hours. This leads to the inevitable conundrum of needing to reinit your ColdBox application to pick up said changes. If ColdBox is reinitted while a server is under load, some users may get errors, so it's a very common to get questions about how to handle that.
Everybody updates their code. Some more than others, and many during business hours. This leads to the inevitable conundrum of needing to reinit your ColdBox application to pick up said changes. If ColdBox is reinitted while a server is under load, some users may get errors, so it's a very common to get questions about how to handle that.
Mid-Flight Modifications
Reinitting the framework while users are on a server is kind of like replacing the wings on an airplane while it's in the air. It's an inherently destructive operation. First, post shutdown hooks are called that shut down aspects like Wirebox, LogBox, and CacheBox. Then the entire framework is destroyed and the application scope wiped clean so no bits are left behind and it can all be garbage collected.
Next, a fresh copy of the framework is built using the new settings, handlers, and services and put in place so it can start processing requests. That might only take a few seconds (or perhaps it takes a lot of seconds if you are loading and caching a ton of data). Either way, there's two types of requests that pose problems during that process:
- Existing requests that were already running when the reinit started (like a long running report or scheduled task)
- New requests that come in after the reinit process is already underway.
Sometimes, these requests are able to process through just fine if they miss the narrow window where the framework is coming back up. Other times they error out and that might not be ideal for your users. There are 3 basic ways to approach reinits under load and they are as follows:
- Allow user requests to run during the reinit. (ColdBox default)
- Fail fast with a maintenance page until the site is back up
- Force thread safety during reinit.
These each have their pros and cons which we'll discuss below.
Golden Parachute
So, before I go any farther, I have to point out that this entire topic is really superseded by the following advice:
Don't reinit a server while it's under load. Ever.
The "correct" process is to reload code like so:
- Drain current requests/users from the server
- Remove it from the load balancer or traffic rotation
- Update the code
- "warm up" the server by hitting it and making sure everything is ready to go
- Place the server back in the pool
This is made incredibly easy with technology like Docker Swarm. In fact, every step above can be completely automated and happen in a number of seconds without any manual changes needed to a load balancer appliance. We are getting in Docker Swarm right now and it is solving so many of these deployment concerns for us, I wish it existed years ago. However, not all of you have the luxury of controlling the entire environment that you're deploying to, or even choosing your technology stack. Many of you only really have control of the code, so that's why I'm still writing this guide :)
In-Flight Service
To facilitate this post, I have created a sample repo on GitHub.
https://github.com/bdw429s/coldbox-reinit-examples/
You can clone the repo, run box install and box start to fire up the examples, but I provided the repo mostly so you'd have the code for a references. There is a branch in the repo for each example. Here's what I have set up:
- This is a simple ColdBox app based on our advanced script template.
- There is a 500ms sleep on the main event just to simulate a site that does more work than "hello world"
- There is a 1 second sleep on app startup to simulate a site that takes a short bit to come up. The longer your site takes to reinit, the more accentuated the patterns will be.
- The JMeter test does two things. The first one is it spins up 75 threads that hammer the home page for exactly 10 seconds
- The second thing the JMeter script does is wait 5 seconds and then fire a single reinit request that falls halfway through the first onslaught of requests
- I installed the Plugin Manager into JMeter and then checked the box to add the "3 Basic Graphs" and "5 Additional Graphs" plugins. That's where my screenshots came from
Default Protocol
Let's take a look at what ColdBox does out of the box when a framework reinit happens. This is represented on the master branch of the repo.
- An exclusive lock is obtained by the request who actually reloads the framework so only one reload happens at a time
- Any other threads running a "normal" request are not queued or blocked in any way
- The reinit does not wait for all executing threads to complete
Let's take a look at how the server behaves when a reinit comes in under load. Click the thumbnails to see the full image.
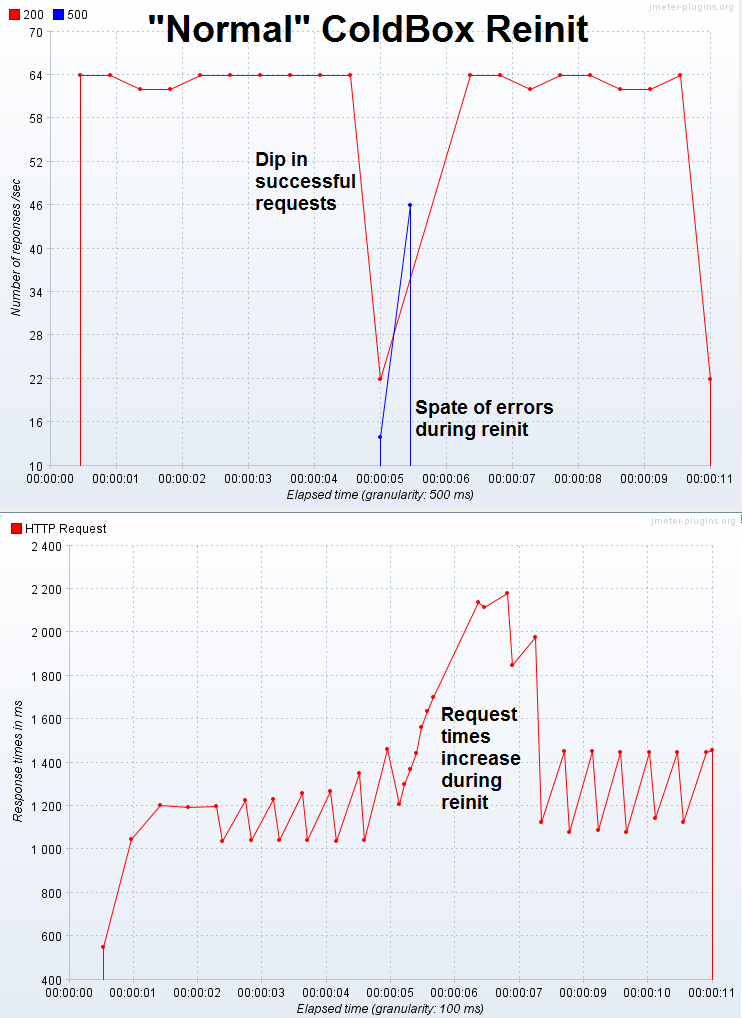
Pros
- This keeps good throughput since incoming requests are not queued and won't back up the server
- It doesn't let the incoming requests just pile up and take down the server
- For a site that's not getting heavy load, you'd probably see few errors
Cons
- It is possible that users will receive an error if their request hits the site at the same time a reinit is happening
On this topic, there's also a nice module for ColdBox called "autoreload' that will fire a reinit for you when a special file has the timestamp updated. This is great for clustered deploys where you can't feasibly reinit all the servers manually. The module can be found here and I added an extra branch to the repo called "auto-deploy" that shows this in action along with a modified JMeter script that calls an action that just manually touches the timestamp on the deploy tag.
We're Currently Experiencing Turbulence
Switch the Git repo to the fail-fast branch and you'll see an example of how to perform a fail-fast maneuver in which users hitting your site will get an immediate "under maintenance" message.
- All changes are within the Application.cfc file
- This one is a little messy since I basically had to rip all the reload checks logic out of the ColdBox bootstrap to change how it works. I've entered a ticket to help make that easier.
- This method sets a boolean variable when a reinit is underway and uses a finally block to set it back when the reinit is done
- This variable controls the fail fast message.
- I returned a 501 status code for the maintenance page so JMeter would report it separately in the graph
Let's take a look at how the server behaves when a reinit comes in under load with fail fast set up. Click the thumbnails to see the full image.
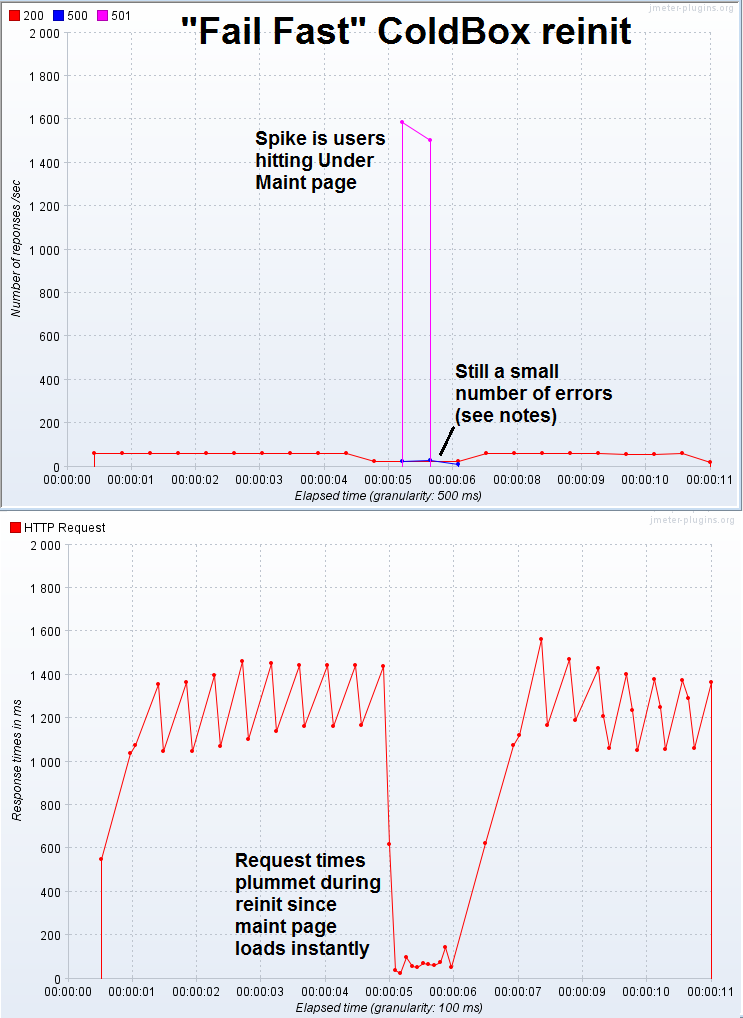
Pros
- This method also has great throughput since requests are not queued
- Users don't sit and watch the site spin, but get instant feedback
- Instead of request times increasing, they actually decrease since the maintenance page is instant
- Almost all errors are gone (see below)
Cons
- This isn't as seamless to your users and might make you look like a noob. (Twitter fail whale, anyone?)
- This can screw up people who were in the middle of a form post or something
- If you look closely, you'll see a few errors still happened. This is from requests that were already running before the reinit started. I purposefully let it this way, since waiting for existing requests could take a long time depending on what's running.
Controlled Descent
Switch the Git repo to the Forced-thread-safety branch to see what it takes to make your reinits never step on the toes of any other request without punting with an error message.
- All changes are within the Application.cfc file
- This is often how people assume ColdBox works by default
- There is already an exclusive lock around the actual reinit code, this change simply wraps a read only lock around any "normal" execution
- This ensures the reinit won't start until all requests are finished
- All incoming requests will queue up until the reinit is good and done
Let's take a look at how the server behaves when a reinit comes in under load with thread safe set up. Click the thumbnails to see the full image.
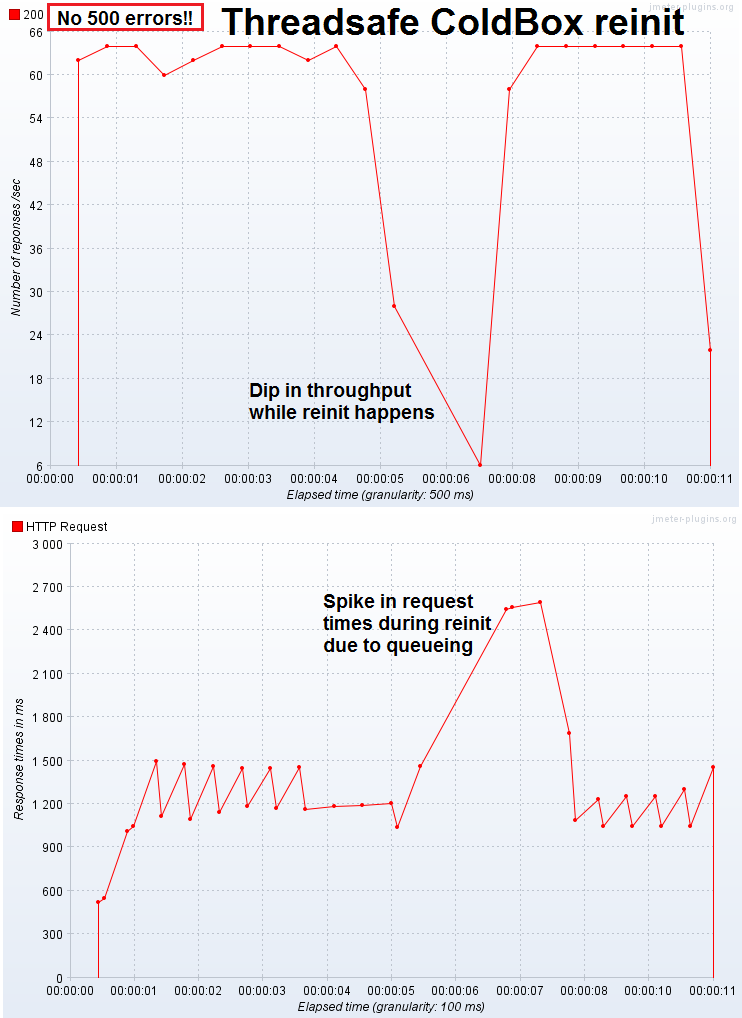
Pros
- There are no errors. Not a single one
- All requests are eventually served
- The user never has to see a fail whale
Cons
- Throughput goes in the can while the reinit is running and site doesn't seem responsive
- If you have some sort of long-running report or job, the reinit can appear to hang for a long time
- If the reinit takes a while, a very large amount of threads can back up
- If your site has enough load, these queued threads can lock up the server. The more the load and the longer the reinits, the worse this one will perform
- ColdBox used to try and acheive his by default, but we changed the behavior because it caused too many server failures in real world scenarios
Mixed Snacks
So, you aren't limited to these exact options; you can mix and match some techniques. For instance, the issues of the few errors in the fail safe method coming from requests that were already underway when the reinit started can be mitigated by combining fail safe with thread safe. Basically you would gain the pro of having no errors but you would gain the con of the reinit not being able to start until all requests were done which might take some time.
As you've probably guessed, the "correct" solution for you really depends on which of the pros you require and which of the cons you are willing to live with. Hopefully this post helps you understand the difference between the approaches. The code samples should give you an idea of how to implement them in your apps. Thanks for flying the friendly Internet with Coldbox and if you're future development plans bring you to MVC, we hope to see you again.



Add Your Comment
(1)
May 28, 2017 10:42:07 UTC
by Joseph Gooch
I wish there were another strategy.... Copy then write essentially. Since wirebox already has a prefix for all it's keys in shared scope, why not increment them each re-init? Would go something like this. 1) Site is running on an initialized application 2) Each request pulls down wirebox into request scope on request start. Similar for any other references to wirebox, and the page can hold read-only locks on a shared key for that instance. (Maybe including the wirebox instance uuid) 3) When a reinit happens, do NOT call shutdown - instead, create a new wirebox instance, with a new wirebox key, new singleton scope, etc. Essentially the application is built in parallel. Do NOT update the Application.wirebox reference or shared reference pointer until the entire application is initialized. Since object scopes would be keyed with a new identifier in shared scopes, i.e. wirebox2:whatever, it will not conflict with anything already running, and existing pages will continue to use the old instances. 4) Once the new objects are complete, save the reference to the new objects as necessary. (i.e. Application.wirebox, Application.coldbox, whatever). Note this is the only part that needs an exclusive lock - with a forced thread safety model perhaps, but it's quick since it's just a cfset or two. (And the only other read-only parts would be reading this pointer in other threads, which are also a quick cfset or two) 5) At this point all new requests use the new objects, all old requests that haven't terminated yet are still using the old objects. 6) Some point in the future, when you're sure all old requests have finished, run shutdown on the old objects. This could be a scheduled task, or a spawned thread that waits for all old requests to finish. Perhaps a CountDown latch or eventlistener concept that can count pages in use as part of the wirebox instance. It essentially implements the same thing the docker instances + loadbalancer would do, without having to start a brand new CF instance. I would do this myself but the wirebox prefix is currently hardcoded as wirebox:.... So it'll take some modification. Sure, docker swarm is great - but it does require a bunch of other infrastructure in place before it's even possible. :)